Anda sedang mencari model AI yang bisa menangani pekerjaan coding rumit tanpa pengawasan ketat, membaca dokumen panjang tanpa kehilangan konteks, atau menganalisis gambar beresolusi tinggi secara akurat? Claude Opus 4.7 hadir sebagai jawaban konkret untuk semua kebutuhan tersebut.
Artikel ini mengurai setiap keunggulan Opus 4.7 berdasarkan data benchmark resmi dari Anthropic, lengkap dengan angka-angka yang bisa Anda jadikan acuan keputusan.
Sebagai konteks, Claude Opus 4.7 bukan sekadar versi minor dari pendahulunya. Berdasarkan pengujian internal Anthropic dan feedback dari puluhan mitra early-access seperti Cursor, Replit, Notion, dan Harvey, model ini menunjukkan lompatan performa yang terukur di hampir semua kategori evaluasi.
Performa Coding Claude Opus 4.7
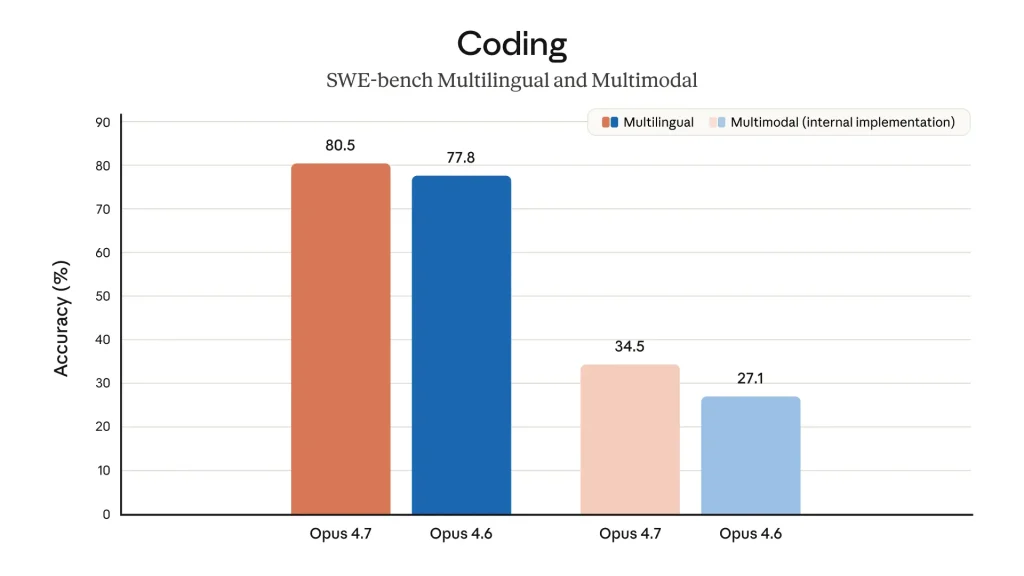
Claude Opus 4.7 mencatat skor 80,5% pada benchmark SWE-bench Multilingual, naik dari 77,8% milik Opus 4.6.
Selisih ini terlihat kecil di atas kertas, tapi dalam praktiknya berarti model ini bisa menyelesaikan lebih banyak bug nyata di codebase produksi yang kompleks dan multilingual.
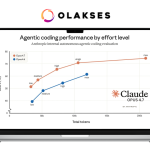
Pada evaluasi agentic coding internal Anthropic, Opus 4.7 menunjukkan kurva performa yang jauh lebih konsisten dibanding Opus 4.6 di semua level effort: low, medium, high, xhigh, hingga max. Di effort level “max” dengan total token sekitar 200 ribu, Opus 4.7 mencapai skor mendekati 75%, sementara Opus 4.6 mentok di sekitar 62%.
Ini berarti untuk task coding panjang dan otomatis, Opus 4.7 adalah pilihan yang lebih efisien secara token maupun hasil.
Dari sisi feedback mitra, CursorBench mencatat Opus 4.7 membersihkan 70% tugas dibanding Opus 4.6 yang hanya 58%. Sementara Rakuten melaporkan Opus 4.7 menyelesaikan 3 kali lebih banyak production task dibanding Opus 4.6, dengan peningkatan dua digit di Code Quality dan Test Quality. CodeRabbit melaporkan peningkatan recall lebih dari 10% untuk bug detection di PR paling kompleks mereka, tanpa penurunan presisi.
Skor Perilaku dan Safety: Lebih Terpercaya dari Generasi Sebelumnya
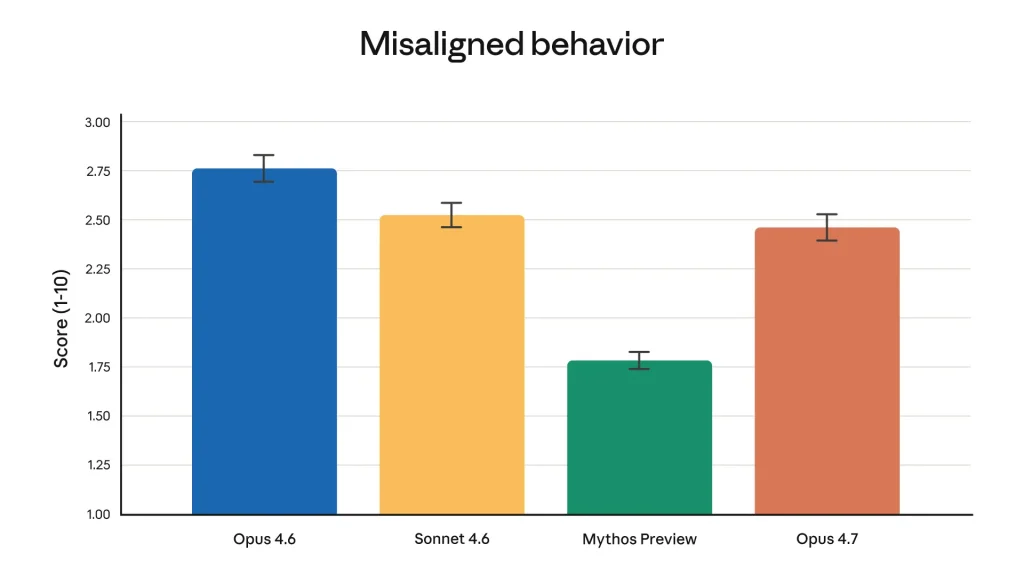
Claude Opus 4.7 menunjukkan profil keamanan yang lebih baik dibanding Opus 4.6 dan Sonnet 4.6 di sebagian besar dimensi penilaian. Dalam automated behavioral audit Anthropic, skor misaligned behavior Opus 4.7 berada di 2,46 (skala 1-10), lebih rendah dari Opus 4.6 yang mencapai 2,75. Angka yang lebih rendah di sini berarti lebih aman, karena skor mengukur frekuensi perilaku yang tidak selaras.
Anthropic menegaskan bahwa Opus 4.7 menunjukkan tingkat rendah pada perilaku bermasalah seperti deception, sycophancy, dan kerjasama dengan penyalahgunaan. Di dimensi honesty dan ketahanan terhadap prompt injection attack, Opus 4.7 bahkan lebih baik dari Opus 4.6.
Catatan penting: Mythos Preview tetap menjadi model paling well-aligned dalam evaluasi internal Anthropic, tapi Opus 4.7 adalah model yang tersedia untuk publik dengan safety profile terbaik saat ini.
Untuk keamanan siber, Anthropic meluncurkan Opus 4.7 dengan safeguards yang secara otomatis mendeteksi dan memblokir permintaan untuk penggunaan cybersecurity berisiko tinggi. Professional keamanan yang membutuhkan kemampuan ini untuk keperluan legitimate (vulnerability research, penetration testing, red-teaming) dapat mendaftar ke Cyber Verification Program dari Anthropic.
Kemampuan Pemrograman Multimodal: Membaca Visual seperti Senior Dev
Opus 4.7 memperkenalkan dukungan gambar resolusi tinggi yang signifikan: model ini sekarang bisa menerima gambar hingga 2.576 piksel di sisi panjangnya, setara dengan sekitar 3,75 megapiksel. Angka ini lebih dari tiga kali lipat dibanding model Claude sebelumnya.
Untuk konteks pemrograman, ini membuka kemampuan baru seperti membaca screenshot padat dari IDE, mengekstrak data dari diagram teknis kompleks, dan menganalisis UI dengan referensi piksel yang presisi.
Pada benchmark SWE-bench Multimodal (internal implementation), Opus 4.7 mencapai 34,5% dibanding Opus 4.6 yang hanya 27,1%, sebuah peningkatan 7,4 poin persentase untuk tugas coding yang melibatkan pemahaman visual.
Vercel melaporkan Opus 4.7 bahkan melakukan “proof” pada systems code sebelum mulai bekerja, sebuah perilaku baru yang belum pernah dilihat dari model Claude sebelumnya.
Kemampuan multimodal ini juga berdampak langsung pada pekerjaan di luar coding murni. Solve Intelligence, platform life sciences patent, menggunakan Opus 4.7 untuk membaca struktur kimia dan menginterpretasikan diagram teknis kompleks, sesuatu yang sebelumnya tidak reliabel dengan Opus 4.6.
Koherensi Jangka Panjang: Tidak Hilang Arah di Tengah Task Panjang
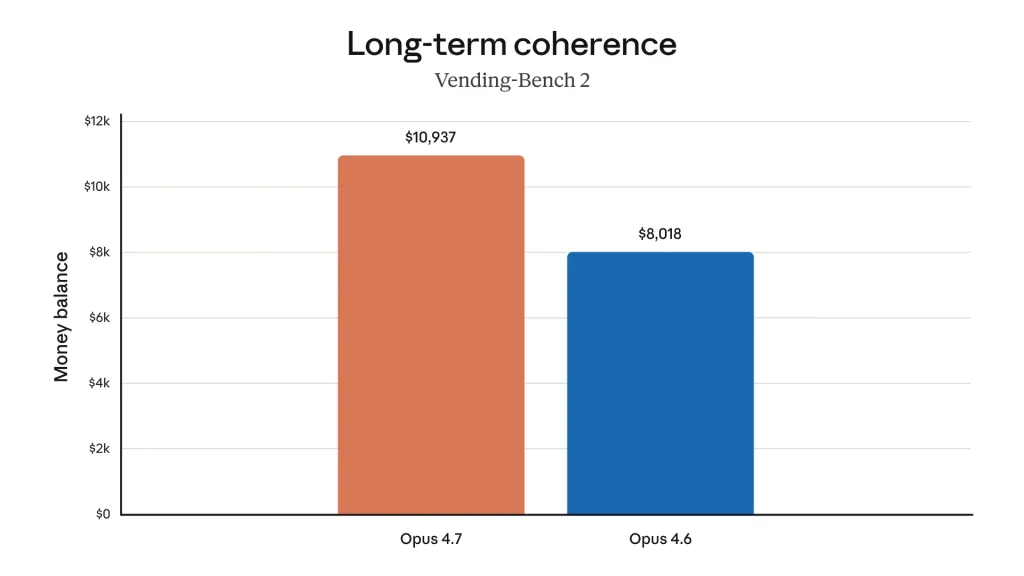
Salah satu kelemahan model AI generasi sebelumnya adalah kehilangan konsistensi saat menangani task multi-step yang panjang. Claude Opus 4.7 mengatasi ini secara konkret. Pada benchmark Vending-Bench 2 yang mengukur long-term coherence, Opus 4.7 mencapai saldo $10.937 dibanding $8.018 untuk Opus 4.6, sebuah perbedaan yang menunjukkan kemampuan planning dan eksekusi jangka panjang yang lebih unggul.
Opus 4.7 juga menghadirkan kemampuan memori berbasis file system yang lebih baik: model ini mengingat catatan penting lintas sesi kerja panjang dan menggunakannya untuk memulai task baru dengan lebih sedikit konteks awal.
Devin (platform autonomous software engineering) melaporkan Opus 4.7 “bekerja secara koheren selama berjam-jam, mendorong melewati masalah sulit alih-alih menyerah,” membuka kelas pekerjaan investigasi mendalam yang sebelumnya tidak bisa diandalkan.
Notion AI Lead melaporkan peningkatan 14% dibanding Opus 4.6 dengan lebih sedikit token dan sepertiga dari tool error, menjadikan Opus 4.7 model pertama yang lulus implicit-need tests mereka. Factory Droids juga melaporkan peningkatan 10-15% dalam task success rate, dengan validasi yang lebih lengkap dan eksekusi yang tidak berhenti di tengah jalan.
Biologi dan Penalaran Saintifik: Lompatan Lebih dari Dua Kali Lipat
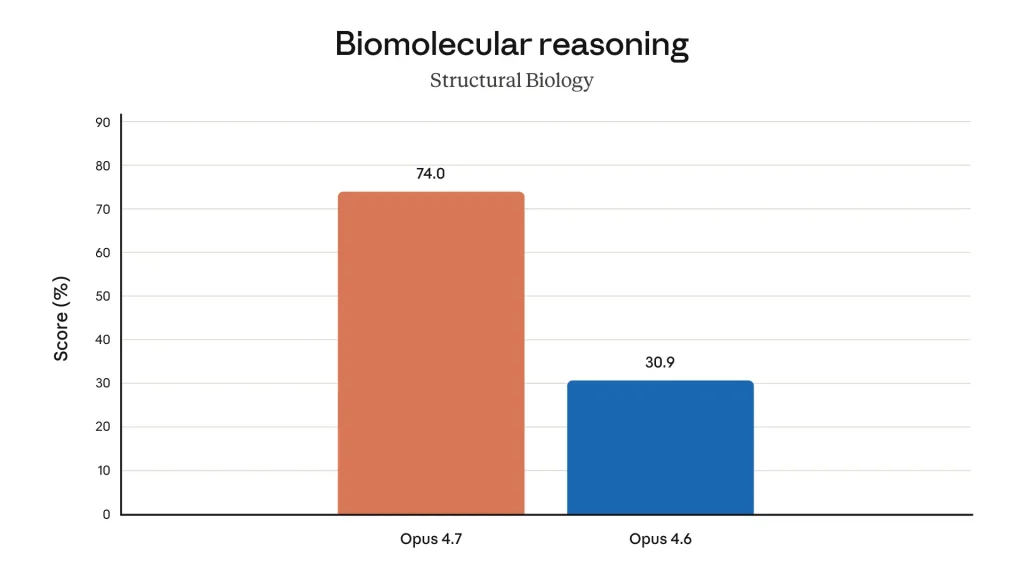
Di domain sains, khususnya biologi molekuler, Claude Opus 4.7 menunjukkan peningkatan yang paling dramatis. Pada benchmark Structural Biology (biomolecular reasoning), Opus 4.7 meraih skor 74%, sementara Opus 4.6 hanya mencapai 30,9%. Ini adalah peningkatan lebih dari dua kali lipat dalam kemampuan penalaran biologi molekuler, termasuk pemahaman struktur protein, interaksi biomolekular, dan analisis data bioinformatika.
Kemampuan ini langsung berdampak pada industri life sciences. Solve Intelligence menggunakan peningkatan multimodal Opus 4.7 untuk membangun alat life sciences patent workflow kelas terbaik, mulai dari drafting dan prosecution hingga infringement detection dan invalidity charting. Kemampuan membaca struktur kimia yang sebelumnya tidak akurat kini menjadi reliable dengan Opus 4.7.
Ini relevan tidak hanya untuk peneliti, tapi juga untuk enterprise yang menggunakan AI dalam pengembangan produk farmasi, analisis material, atau riset bioteknologi. Claude Opus 4.7 membuka pintu untuk otomasi tugas-tugas yang sebelumnya memerlukan keahlian manusia yang sangat spesifik.
Penalaran Konteks Panjang: Unggul di 1 Juta Token
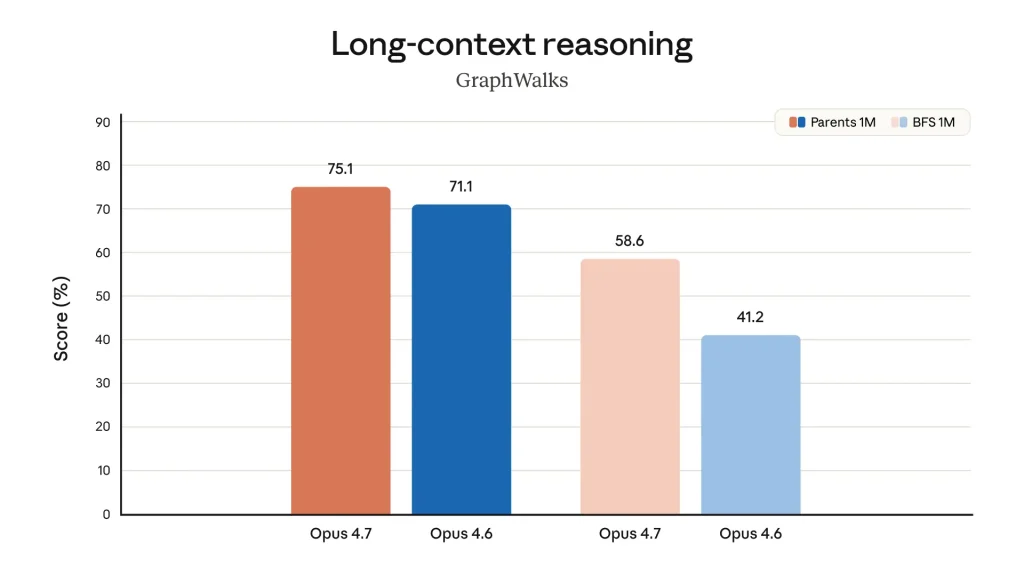
Claude Opus 4.7 diuji pada benchmark GraphWalks yang mengukur kemampuan penalaran di konteks sangat panjang hingga 1 juta token. Hasilnya: Opus 4.7 mencapai 75,1% untuk Parents 1M dan 58,6% untuk BFS 1M, sementara Opus 4.6 mencatat 71,1% dan 41,2% di kategori yang sama. Peningkatan di BFS (Breadth-First Search) 1M adalah yang paling menonjol, naik 17,4 poin persentase.
Kemampuan ini sangat relevan untuk use case enterprise: analisis kontrak hukum ratusan halaman, riset finansial dari ribuan dokumen sekaligus, atau debugging codebase besar yang tersebar di banyak file. Michal Mucha dari perusahaan AI riset melaporkan Opus 4.7 memberikan “performa long-context paling konsisten dari model manapun yang mereka uji,” dengan skor keseluruhan 0,715 dan hasil terbaik di General Finance module (0,813 vs 0,767 untuk Opus 4.6).
Khusus untuk pekerjaan hukum, Harvey mencatat akurasi substantif 90,9% di effort tinggi pada BigLaw Bench, dengan penanganan lebih baik untuk review table dan pengeditan dokumen ambigu. Opus 4.7 bahkan berhasil membedakan assignment provisions dari change-of-control provisions, sebuah tugas yang selama ini menantang model frontier manapun.
Alasan Dokumen dan Penglihatan: Terbaik di Kelasnya
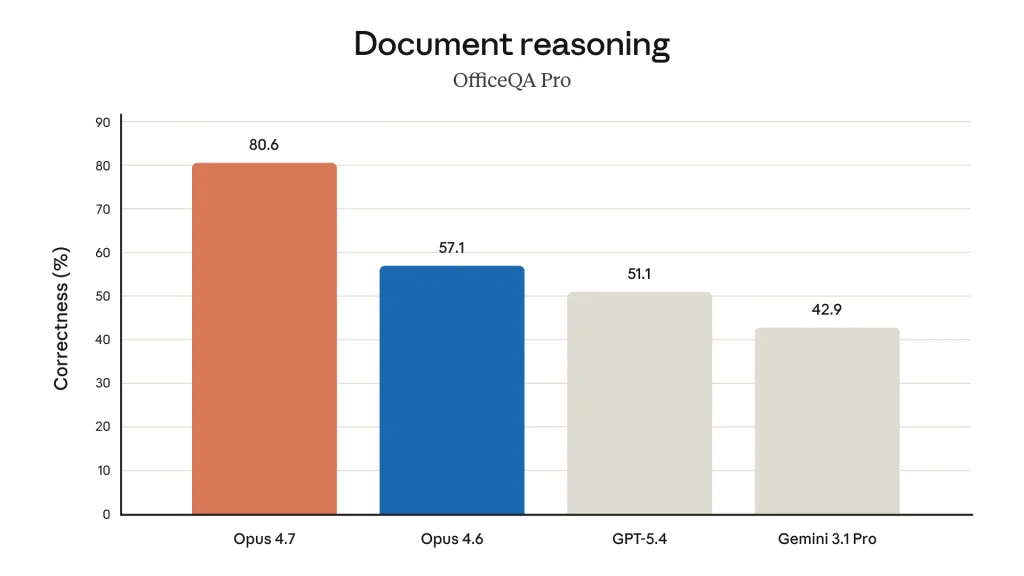
Document reasoning adalah area di mana Claude Opus 4.7 paling menonjol dibanding kompetitornya. Pada benchmark OfficeQA Pro, Opus 4.7 mencapai 80,6% correctness, jauh melampaui Opus 4.6 (57,1%), GPT-5.4 (51,1%), dan Gemini 3.1 Pro (42,9%). Selisih 23,5 poin persentase dari Opus 4.6 ke Opus 4.7 adalah lompatan yang sangat besar untuk dokumen reasoning.
Databricks mengkonfirmasi hasil ini: Opus 4.7 menunjukkan 23% lebih sedikit error dibanding Opus 4.6 saat bekerja dengan source information dokumen, menjadikannya model Claude terbaik untuk enterprise document analysis. Untuk Anda yang sering bekerja dengan dokumen kompleks seperti laporan keuangan, brief hukum, atau whitepaper teknis, ini adalah alasan yang sangat konkret untuk beralih ke Opus 4.7.
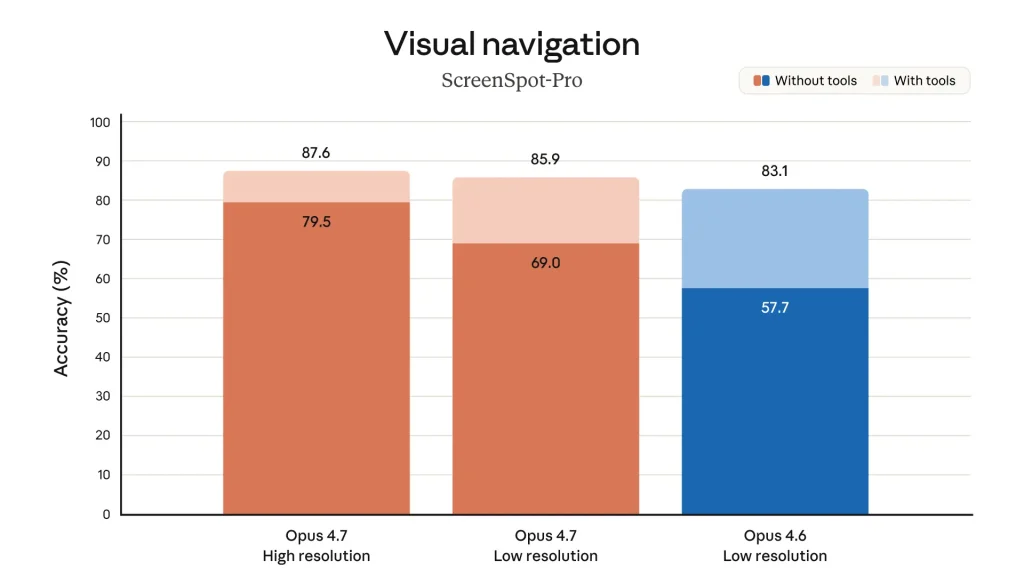
Untuk kemampuan visual navigation (ScreenSpot-Pro), Opus 4.7 high resolution mencapai 87,6% (dengan tools) dan 79,5% (tanpa tools), dibanding Opus 4.6 yang hanya 83,1% dan 57,7%. XBOW, platform autonomous penetration testing, melaporkan visual-acuity benchmark mereka naik dari 54,5% (Opus 4.6) ke 98,5% (Opus 4.7), sebuah peningkatan yang praktis menghilangkan hambatan terbesar mereka dalam menggunakan Claude untuk computer-use work.
Tugas Kantor dan Knowledge Work: Opus 4.7 Memimpin GDPVal-AA
Untuk pekerjaan kantoran yang bernilai ekonomi nyata, Claude Opus 4.7 meraih Elo score 1.753 pada benchmark GDPVal-AA dari Artificial Analysis, jauh melampaui GPT-5.4 (1.674), Opus 4.6 (1.619), dan Gemini 3.1 Pro (1.314). GDPVal-AA adalah evaluasi pihak ketiga yang mengukur pengetahuan kerja yang secara ekonomi berharga di domain finance, hukum, dan domain lainnya.
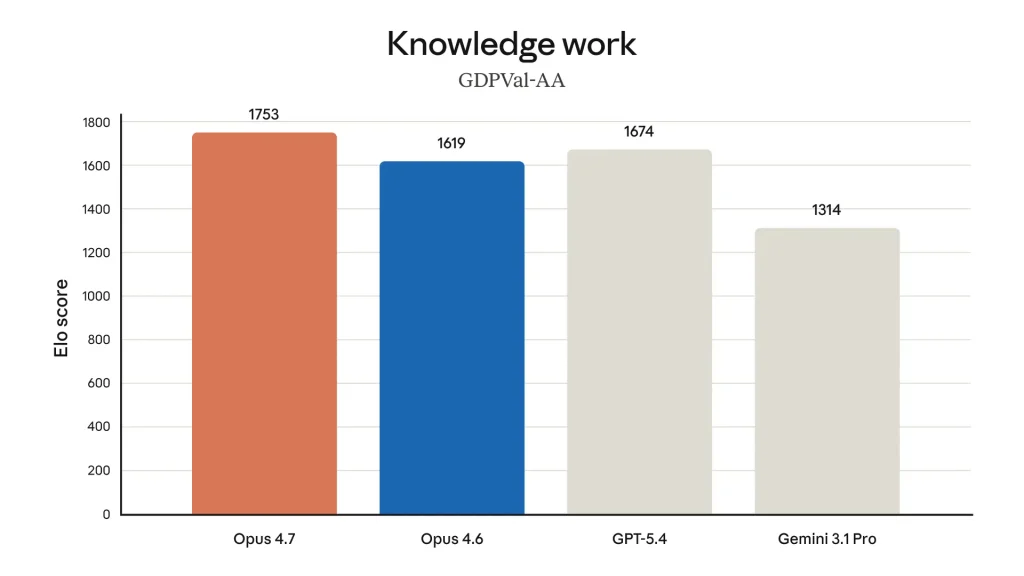
Dalam pengujian internal Anthropic, Opus 4.7 terbukti menjadi finance analyst yang lebih efektif dari Opus 4.6: menghasilkan analisis yang lebih ketat, model yang lebih profesional, presentasi yang lebih baik, dan integrasi yang lebih kencang antar task. Untuk tugas kantor sehari-hari seperti membuat slide, dokumen, dan laporan, Opus 4.7 juga lebih “tasteful” dan kreatif dibanding pendahulunya.
Bagi Anda yang menggunakan Claude untuk produktivitas profesional, perbedaan ini terasa nyata. Model ini tidak hanya menjawab pertanyaan dengan lebih akurat, tapi juga menghasilkan output yang lebih siap pakai dengan sedikit revisi manual.
Ringkasan Perbandingan Benchmark Claude Opus 4.7
| Benchmark | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro | Sumber |
|---|---|---|---|---|---|
| SWE-bench Multilingual (coding) | 80,5% | 77,8% | N/A | N/A | Anthropic, 2026 |
| OfficeQA Pro (document reasoning) | 80,6% | 57,1% | 51,1% | 42,9% | Anthropic, 2026 |
| GDPVal-AA (knowledge work, Elo) | 1753 | 1619 | 1674 | 1314 | Artificial Analysis, 2026 |
| Structural Biology (bio reasoning) | 74,0% | 30,9% | N/A | N/A | Anthropic, 2026 |
| GraphWalks Parents 1M (long-context) | 75,1% | 71,1% | N/A | N/A | Anthropic, 2026 |
| Vending-Bench 2 (long-term coherence) | $10.937 | $8.018 | N/A | N/A | Anthropic, 2026 |
| ScreenSpot-Pro Visual Nav (w/ tools) | 87,6% | 83,1% | N/A | N/A | Anthropic, 2026 |
| Misaligned Behavior Score (lebih rendah lebih baik) | 2,46 | 2,75 | N/A | N/A | Anthropic System Card, 2026 |
Feedback Mitra Early-Access: Data dari Implementasi Nyata
| Perusahaan | Use Case | Hasil Terukur | Dibanding Opus 4.6 |
|---|---|---|---|
| Cursor | Coding benchmark internal | 70% task completion | +12pp dari 58% |
| Rakuten | Production tasks (SWE-Bench) | 3x lebih banyak task terselesaikan | +dua digit di Code Quality |
| Harvey | BigLaw Bench (hukum) | 90,9% substantive accuracy (high effort) | Penanganan dokumen ambigu lebih baik |
| Notion | Multi-step agent workflows | +14% task success, 1/3 tool errors | Model pertama lulus implicit-need tests |
| XBOW | Autonomous penetration testing | 98,5% visual-acuity benchmark | Naik dari 54,5% (Opus 4.6) |
| Hex | Data analysis platform | Akurasi tinggi tanpa fallback palsu | Low-effort 4.7 setara medium-effort 4.6 |
| Factory Droids | Enterprise engineering agents | +10-15% task success rate | Eksekusi lebih complete tanpa berhenti |
Spesifikasi dan Ketersediaan Claude Opus 4.7
| Parameter | Detail | Referensi |
|---|---|---|
| API Model String | claude-opus-4-7 | Claude API Docs |
| Harga Input | $5 per juta token | Anthropic, 2026 |
| Harga Output | $25 per juta token | Anthropic, 2026 |
| Resolusi Gambar Maksimum | 2.576 piksel (panjang), sekitar 3,75 megapiksel | Claude Vision Docs |
| Effort Levels Tersedia | low, medium, high, xhigh, max | Claude Effort Docs |
| Platform Tersedia | Claude.ai, API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry | Anthropic, 2026 |
| Tanggal Rilis | 16 April 2026 | Anthropic, 2026 |
| Migration Guide | Tersedia resmi dari Anthropic | Claude Migration Guide |
Cara Mulai Menggunakan Claude Opus 4.7 Sekarang
Claude Opus 4.7 sudah tersedia hari ini di semua produk Claude, API Anthropic, Amazon Bedrock, Google Cloud Vertex AI, dan Microsoft Foundry. Jika Anda sudah menggunakan Opus 4.6 melalui API, cukup ganti model string ke claude-opus-4-7 dan Anda langsung mendapatkan semua peningkatan yang sudah dijelaskan di atas.
Ada dua hal penting yang perlu Anda ketahui sebelum migrasi. Pertama, Opus 4.7 menggunakan tokenizer yang diperbarui sehingga input yang sama bisa menghasilkan lebih banyak token (sekitar 1,0 hingga 1,35 kali lipat tergantung tipe konten).
Kedua, Opus 4.7 berpikir lebih banyak di effort level tinggi, khususnya di turn-turn berikutnya dalam sesi agentic. Anthropic menyediakan migration guide resmi yang membahas cara menyesuaikan prompt dan effort level agar token usage tetap efisien.
Untuk pengguna Claude Code, effort level default sudah dinaikkan ke xhigh untuk semua plan. Anthropic juga meluncurkan perintah /ultrareview baru di Claude Code yang menghasilkan review session khusus untuk mendeteksi bug dan design issue, dengan tiga ultrareview gratis untuk pengguna Pro dan Max.
Key Takeaway: Mengapa Claude Opus 4.7 Layak Jadi Pilihan Utama Anda
Claude Opus 4.7 bukan sekadar update inkremental. Model ini menghadirkan lompatan nyata di coding agentic, pemahaman dokumen (+23,5pp di OfficeQA Pro), penalaran biologi (+43pp), dan koherensi jangka panjang (+36% di Vending-Bench 2). Untuk Anda yang bekerja dengan task kompleks, multi-step, atau membutuhkan AI yang tidak “menyerah” di tengah pekerjaan, Opus 4.7 adalah upgrade yang konkret dan terukur. Dengan harga yang sama seperti Opus 4.6, tidak ada alasan untuk tidak beralih.
FAQ: Pertanyaan yang Sering Diajukan tentang Claude Opus 4.7
Q1: Apakah Claude Opus 4.7 lebih mahal dari Opus 4.6?
A: Tidak. Harga Claude Opus 4.7 sama persis dengan Opus 4.6: $5 per juta input token dan $25 per juta output token. Namun perlu diperhatikan bahwa tokenizer baru Opus 4.7 bisa menghasilkan 1,0 hingga 1,35 kali lebih banyak token untuk input yang sama, jadi biaya aktual mungkin sedikit berbeda tergantung use case Anda.
Q2: Di mana Claude Opus 4.7 bisa diakses?
A: Opus 4.7 tersedia di semua produk Claude (claude.ai dan aplikasi Claude), Claude API dengan model string claude-opus-4-7, Amazon Bedrock, Google Cloud Vertex AI, dan Microsoft Foundry. Tidak perlu daftar khusus; cukup update model string di konfigurasi Anda.
Q3: Seberapa besar peningkatan kemampuan coding Opus 4.7 dibanding Opus 4.6?
A: Opus 4.7 meraih 80,5% di SWE-bench Multilingual vs 77,8% untuk Opus 4.6. Di CursorBench, hasilnya 70% vs 58%. Rakuten melaporkan Opus 4.7 menyelesaikan 3x lebih banyak production task dibanding Opus 4.6 di benchmark internal mereka.
Q4: Apakah Claude Opus 4.7 aman digunakan untuk pekerjaan enterprise?
A: Ya. Opus 4.7 menunjukkan skor misaligned behavior yang lebih rendah dari Opus 4.6 dan Sonnet 4.6. Anthropic juga menyertakan safeguards otomatis untuk mendeteksi penggunaan cybersecurity berisiko tinggi. Full safety evaluation tersedia di Claude Opus 4.7 System Card.
Q5: Apa itu effort level xhigh di Claude Opus 4.7?
A: xhigh adalah level effort baru yang diperkenalkan di Opus 4.7, berada antara high dan max. Level ini memberikan kontrol lebih halus antara kedalaman penalaran dan latensi. Di Claude Code, xhigh sudah menjadi default untuk semua plan. Untuk coding dan use case agentic, Anthropic merekomendasikan mulai dari effort high atau xhigh.
Q6: Bagaimana Opus 4.7 dibandingkan dengan GPT-5.4 untuk document reasoning?
A: Opus 4.7 unggul signifikan di OfficeQA Pro dengan 80,6% correctness, dibanding GPT-5.4 yang mencapai 51,1%. Untuk knowledge work secara umum (GDPVal-AA), Opus 4.7 meraih Elo 1.753 vs 1.674 untuk GPT-5.4.
Q7: Apakah ada risiko saat migrasi dari Opus 4.6 ke Opus 4.7?
A: Risiko utama adalah Opus 4.7 mengikuti instruksi secara lebih literal, sehingga prompt yang ditulis longgar untuk Opus 4.6 mungkin menghasilkan output yang tidak terduga. Anthropic menyarankan untuk menyesuaikan prompt dan harness sebelum produksi, dan menyediakan migration guide resmi untuk panduan lebih detail.
Q8: Apakah Claude Opus 4.7 bisa digunakan untuk cybersecurity research?
A: Opus 4.7 memiliki safeguards yang memblokir permintaan cybersecurity berisiko tinggi secara otomatis. Security professional yang membutuhkan kemampuan ini untuk keperluan legitimate bisa mendaftar ke Cyber Verification Program dari Anthropic untuk mendapatkan akses yang terverifikasi.
Butuh Strategi AI yang Tepat untuk Bisnis Anda?
Tim Olakses siap membantu Anda memilih dan mengintegrasikan model AI yang paling sesuai dengan kebutuhan bisnis, mulai dari Claude Opus 4.7 untuk coding dan analisis dokumen, hingga strategi GEO dan SEO berbasis AI untuk meningkatkan visibilitas digital Anda secara menyeluruh.

Muhammad Dwiki Septianto is an SEO Specialist at Olakses with a background in Informatics Engineering from UIN Bandung. Certified in Digital Marketing (BNSP), he specializes in on-page and technical SEO, content optimization, and cross-functional coordination between content and development teams.