Apa Itu Crawl Budget dan Kenapa Ini Penting?
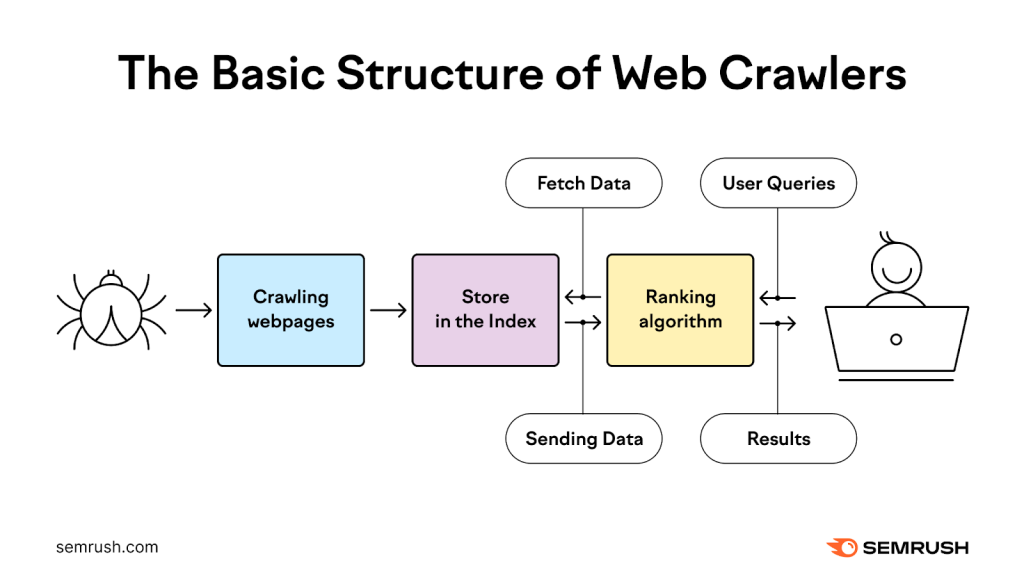
Definisi Crawl Budget Menurut Google
Crawl budget adalah jumlah total waktu dan resource yang dialokasikan Google untuk meng-crawl satu hostname dalam periode tertentu. Ini bukan sekadar “berapa halaman yang dikunjungi Googlebot,” tapi kombinasi dari dua faktor utama: crawl capacity limit (seberapa cepat Googlebot bisa merayapi tanpa membebani server Anda) dan crawl demand (seberapa besar minat Google terhadap URL di website Anda).
Menurut Ahrefs SEO Glossary, crawl budget adalah jumlah halaman maksimum yang bisa dirayapi search engine di website Anda dalam satu jangka waktu tertentu. Angka ini berbeda untuk setiap website, dan bisa berbeda pula antar search engine.
Siapa yang Perlu Khawatir Soal Crawl Budget?
Google sendiri menyatakan bahwa crawl budget menjadi isu kritis untuk website dengan lebih dari 1 juta halaman unik yang kontennya sering berubah, atau website menengah dengan 10.000 halaman ke atas dengan konten yang diperbarui setiap hari. Tapi dalam praktiknya, website dengan 500 halaman pun bisa mengalami masalah crawl budget kalau strukturnya berantakan dan banyak URL sampah yang dirayapi Googlebot terus-menerus.
Dua Komponen Utama yang Menentukan Crawl Budget Anda
Crawl Capacity Limit: Seberapa Kuat Server Anda?
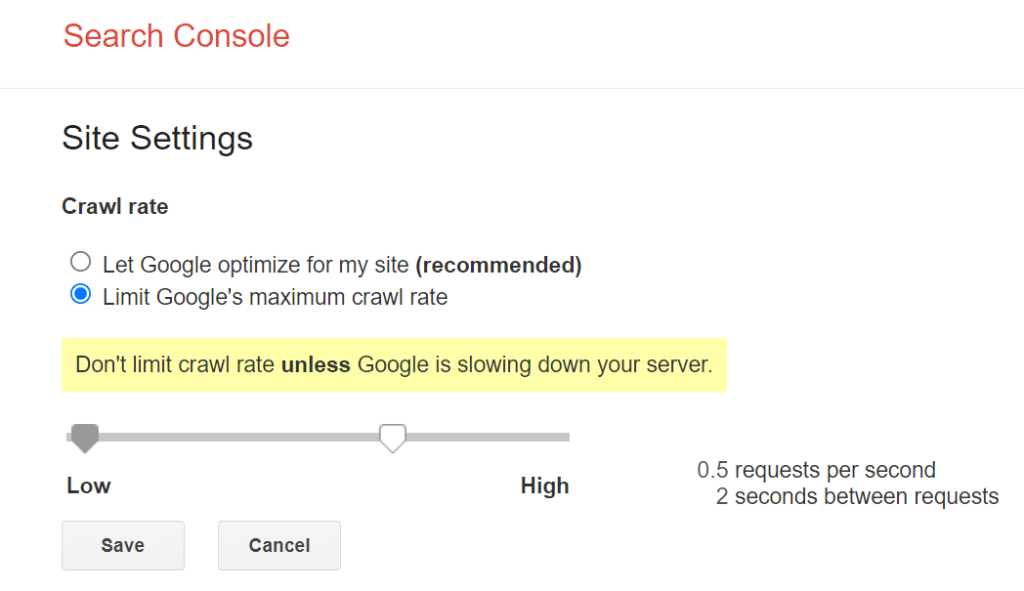
Googlebot menyesuaikan kecepatan crawling-nya berdasarkan respons server website Anda. Kalau server Anda lambat atau sering error, Googlebot akan otomatis memperlambat frekuensi kunjungannya untuk menghindari membebani server. Sebaliknya, server yang cepat dan stabil memberikan sinyal kepada Googlebot bahwa website Anda bisa dirayapi lebih agresif. Ini adalah alasan kuat mengapa page speed bukan hanya soal UX, tapi juga berdampak langsung ke crawl budget.
Crawl Demand: Seberapa Besar Minat Google ke Website Anda?
Sisi lain dari persamaan ini adalah crawl demand, yaitu seberapa sering Google ingin mengunjungi website Anda. Faktor yang memengaruhi ini antara lain popularitas URL (diukur dari backlink dan traffic), seberapa sering konten berubah atau diperbarui, dan apakah Google mendeteksi bahwa ada konten baru yang perlu diindeks. Website dengan authority tinggi dan konten yang diperbarui rutin secara alami akan mendapatkan crawl demand yang lebih besar dari Google.
| Faktor | Dampak ke Crawl Budget | Sumber |
|---|---|---|
| Page speed & server response time | Server lambat = Googlebot kunjungi lebih jarang | Google Crawl Budget Docs |
| Authority domain (backlink) | Authority tinggi = crawl demand lebih besar | Moz Blog |
| URL duplikat & parameter | Membebani crawl budget dengan halaman tidak bernilai | SEMrush |
| Frekuensi update konten | Update rutin meningkatkan crawl demand | Google Search Central |
| Robots.txt & noindex | Blokir halaman tidak penting = hemat crawl budget | Yoast |
Kenapa Indexing Anda Jelek? Ini Penyebab Crawl Budget Terbuang Sia-sia
Halaman Tag dan Kategori yang Tidak Dioptimasi
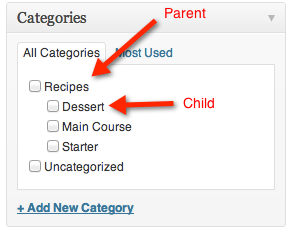
Ini adalah biang kerok nomor satu yang sering diabaikan. Bayangkan WordPress Anda punya 200 artikel, tapi masing-masing artikel punya 5 tag. Itu berarti ada 1.000 halaman tag yang Googlebot berpotensi kunjungi setiap kali merayapi website Anda. Padahal halaman-halaman tag itu hampir tidak punya nilai konten, tidak punya backlink, dan tidak ada yang mencari keyword dari halaman tag tersebut. Akibatnya, crawl budget Anda habis di sana, sementara artikel utama yang sudah Anda susun dengan susah payah justru jarang tersentuh.
URL Parameter dan Filter Produk (Khususnya E-Commerce)
Website e-commerce adalah contoh paling ekstrem dari masalah ini. Satu halaman produk bisa menghasilkan ratusan kombinasi URL hanya dari filter warna, ukuran, dan urutan tampilan. SEMrush mencatat bahwa URL dengan parameter seperti ?color=red&size=M&sort=price adalah salah satu penyebab utama crawl budget terbuang tanpa hasil yang berarti bagi indexing.
Redirect Chain dan Broken Link
Setiap kali Googlebot menemukan redirect, Googlebot harus mengikuti rantai tersebut sampai ke tujuan akhir. Kalau ada redirect chain panjang (A ke B ke C ke D), Googlebot menghabiskan resource untuk proses itu. Backlinko menyebutkan bahwa redirect chain lebih dari dua tingkat sudah bisa memengaruhi efisiensi crawling secara signifikan. Broken link juga bermasalah karena Googlebot tetap mencoba mengaksesnya berulang kali meski responsnya selalu 404.
Halaman Berkualitas Rendah yang Tidak Diblokir
Halaman dengan konten tipis (thin content), halaman hasil pencarian internal website, halaman login, dan halaman print version yang bisa diakses Googlebot adalah pembuang crawl budget yang tidak terlihat. Menurut Yoast, sangat penting untuk secara aktif memblokir halaman-halaman yang tidak perlu diindeks menggunakan kombinasi robots.txt, tag noindex, dan canonical URL.
Cara Cek Crawl Budget Website Anda Sekarang
Gunakan Google Search Console (Crawl Stats)
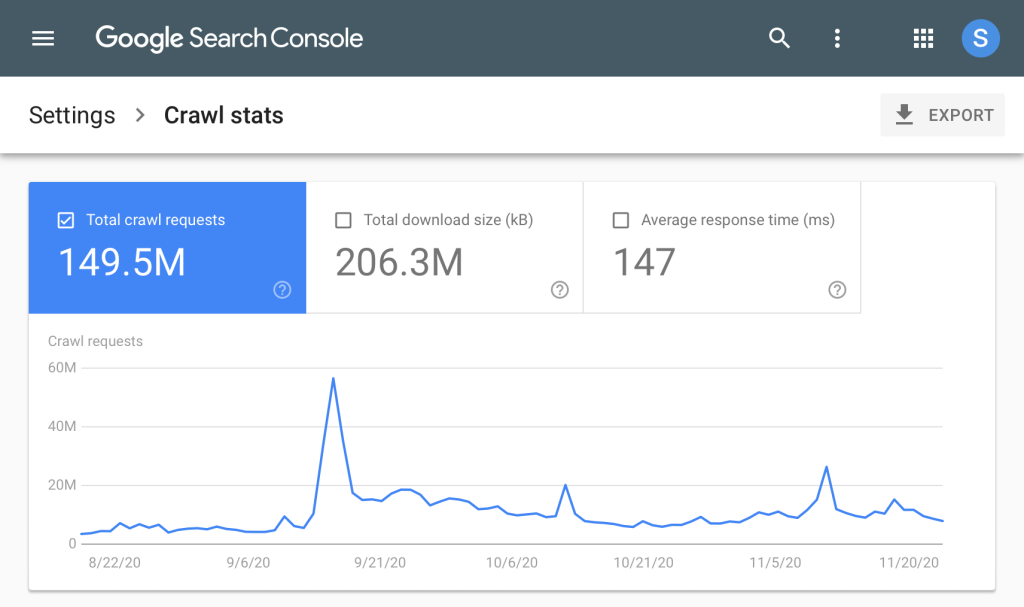
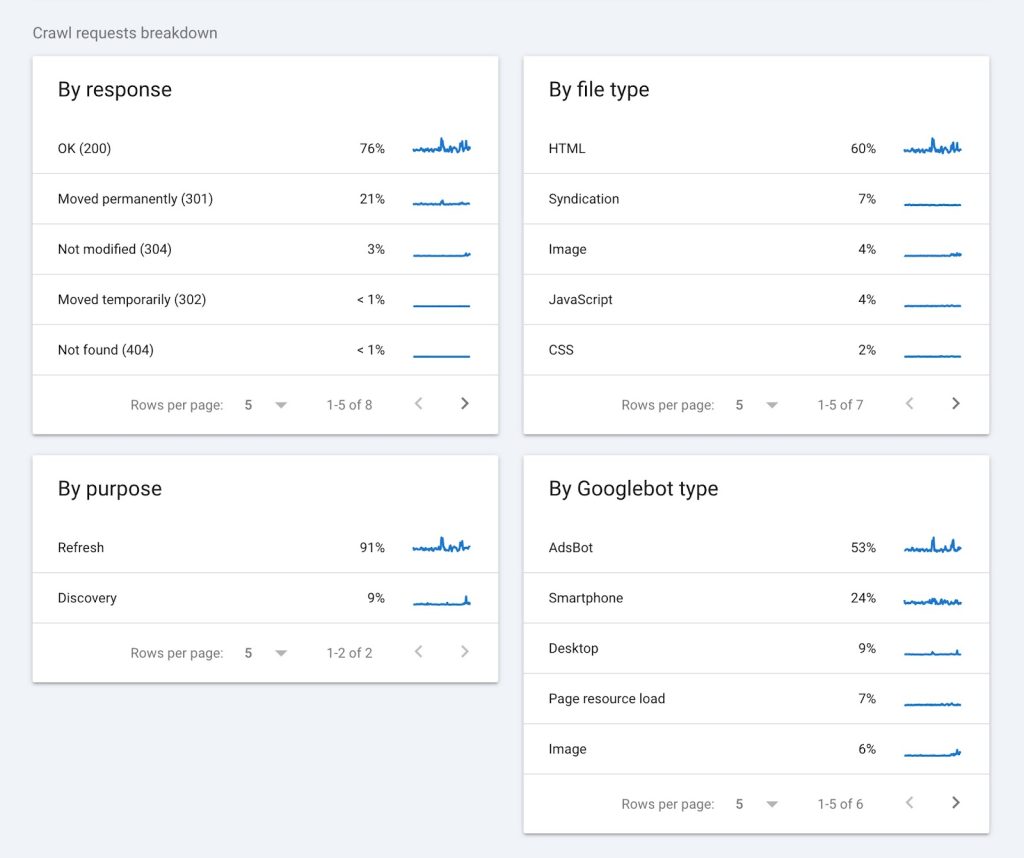
Google Search Console menyediakan laporan Crawl Stats yang menampilkan berapa banyak halaman yang dirayapi Googlebot per hari, rata-rata waktu download per halaman, dan total kilobyte yang didownload. Akses laporan ini melalui menu Settings > Crawl Stats di GSC. Kalau Anda melihat angka crawl rendah tapi total halaman website Anda besar, itu sinyal kuat bahwa ada masalah crawl budget yang perlu diselesaikan.
Analisis Log File Server
Cara paling akurat untuk memahami perilaku Googlebot di website Anda adalah dengan menganalisis server log. Log file mencatat setiap request yang dibuat Googlebot, termasuk URL apa yang dikunjungi, status code yang dikembalikan, dan seberapa sering kunjungan itu terjadi. Dari analisis log ini, Anda bisa langsung melihat apakah Googlebot menghabiskan banyak waktu di halaman-halaman yang tidak penting. Tools seperti Ahrefs Site Audit juga bisa membantu mengidentifikasi halaman mana yang paling sering dirayapi versus yang jarang dikunjungi.
Gunakan Ahrefs atau SEMrush untuk Crawl Audit
Ahrefs Site Audit menampilkan data tentang crawlability halaman per halaman, termasuk mana yang diblokir robots.txt, mana yang noindex, dan mana yang punya isu redirect. Data ini membantu Anda memetakan di mana crawl budget terbuang dan URL mana yang seharusnya diprioritaskan Googlebot tapi justru tidak tersentuh.
| Tool | Data Utama | Cocok Untuk | Link |
|---|---|---|---|
| Google Search Console | Crawl stats harian, error, coverage report | Semua website, gratis | search.google.com |
| Ahrefs Site Audit | Crawlability per halaman, redirect chain, noindex audit | Website menengah-besar, audit mendalam | Ahrefs Academy |
| SEMrush Site Audit | Crawl budget waste, broken links, duplikasi konten | Competitive + teknikal sekaligus | SEMrush Blog |
| Screaming Frog | Log file analysis, redirect mapping, XML sitemap audit | SEO teknikal yang butuh kontrol penuh | Screaming Frog |
Cara Optimasi Crawl Budget: 6 Langkah Praktis
Langkah 1: Blokir Halaman yang Tidak Perlu Diindeks
Audit semua URL di website Anda dan tentukan mana yang tidak perlu diindeks Google. Halaman yang termasuk kategori ini adalah: halaman tag dan kategori tanpa konten unik, halaman hasil pencarian internal, halaman login dan registrasi, halaman print version, dan URL dengan parameter tracking. Gunakan robots.txt untuk memblokir Googlebot mengaksesnya, atau tambahkan tag noindex jika halaman tetap perlu bisa diakses pengguna tapi tidak perlu diindeks.
Langkah 2: Perbaiki Redirect Chain dan Hapus Broken Link
Redirect chain lebih dari satu lompatan harus diperbaiki menjadi direct redirect langsung ke tujuan akhir. Broken link harus segera diperbaiki atau dihapus. Lakukan audit broken link secara rutin menggunakan Ahrefs atau Screaming Frog, dan pastikan setiap redirect sudah bersih tanpa rantai yang panjang. Ini adalah langkah yang paling cepat memberikan dampak terhadap efisiensi crawling.
Langkah 3: Optimalkan XML Sitemap
Sitemap XML Anda harus hanya berisi URL yang benar-benar ingin Anda indeks. Jangan masukkan URL yang sudah noindex, URL dengan canonical ke halaman lain, atau URL yang diblokir robots.txt. Google secara eksplisit menyarankan untuk menjaga sitemap tetap bersih dan hanya berisi URL berkualitas tinggi agar Googlebot bisa memprioritaskan halaman yang benar-benar penting.
Langkah 4: Tingkatkan Page Speed dan Server Response Time
Server yang merespons dalam waktu di bawah 200ms memberi sinyal positif kepada Googlebot bahwa website Anda layak dirayapi lebih sering dan lebih agresif. Investasi di hosting berkualitas, CDN, dan optimasi kode adalah investasi yang berdampak langsung ke crawl budget. Setiap peningkatan kecepatan server secara langsung meningkatkan kapasitas crawl yang bisa dialokasikan Google untuk website Anda. Panduan lengkap soal ini bisa Anda baca di artikel Page Speed Optimization yang Olakses susun khusus untuk konteks SEO teknikal Indonesia.
Langkah 5: Gunakan Canonical URL untuk Mengelola Duplikat
Untuk website e-commerce atau website dengan banyak variasi URL, canonical tag adalah solusi utama. Tentukan satu URL kanonik untuk setiap konten dan arahkan semua variasi URL lainnya ke URL tersebut. Dengan begini, Googlebot tahu halaman mana yang “asli” dan tidak perlu membuang crawl budget untuk menganalisis puluhan variasi URL yang sebenarnya berisi konten yang sama.
Langkah 6: Bangun Internal Link yang Kuat ke Halaman Prioritas
Internal link yang kuat dan strategis membantu Googlebot memahami halaman mana yang paling penting di website Anda. Halaman yang banyak mendapat internal link dari halaman lain secara alami akan lebih sering dikunjungi Googlebot dibanding halaman yang terisolasi tanpa link dari mana pun. Tim Olakses memprioritaskan audit internal link sebagai bagian dari crawl efficiency review, karena pola internal link yang salah sering menjadi penyebab halaman prioritas tenggelam di bawah halaman-halaman sekunder yang tidak produktif. Prioritaskan internal link menuju halaman konten utama Anda, bukan ke halaman tag atau kategori yang tidak berkontribusi pada indexing.
| Tindakan Optimasi | Dampak | Prioritas |
|---|---|---|
| Blokir halaman tag/kategori tidak produktif | Hemat crawl budget signifikan | Tinggi |
| Perbaiki redirect chain | Efisiensi crawling meningkat | Tinggi |
| Bersihkan XML sitemap | Googlebot fokus ke halaman penting | Tinggi |
| Tingkatkan page speed | Crawl capacity limit meningkat | Menengah |
| Implementasi canonical URL | Eliminasi duplikat konten | Menengah |
| Perkuat internal link ke halaman prioritas | Crawl demand halaman utama meningkat | Menengah |
Crawl Budget, Indexing, dan Ranking: Hubungannya Seperti Apa?

Tidak Di-Crawl = Tidak Diindeks = Tidak Bisa Ranking
Ini logika yang sederhana tapi sering dilupakan: sebelum sebuah halaman bisa tampil di hasil pencarian Google, halaman tersebut harus dulu diindeks. Dan sebelum diindeks, halaman tersebut harus dulu dirayapi (crawled) oleh Googlebot. Kalau crawl budget Anda habis di halaman-halaman tidak penting, maka halaman konten terbaik Anda tidak pernah diindeks, dan otomatis tidak bisa ranking untuk keyword apapun.
Crawl Budget Adalah Fondasi dari Strategi Topical Authority
Kalau Anda sedang membangun topical authority dengan ratusan artikel dalam satu kluster topik, crawl budget yang efisien adalah syarat mutlak agar strategi itu berhasil. Google perlu merayapi dan mengindeks semua artikel dalam kluster tersebut untuk memahami bahwa website Anda memang otoritatif di topik itu. Satu artikel yang tidak terindeks karena masalah crawl budget bisa merusak kelengkapan kluster konten yang sudah Anda bangun.
Crawl Budget di Era AI Search: Masih Relevan?
Googlebot Tetap Jadi Gerbang Utama Menuju Index
Di era di mana Google AI Overviews, ChatGPT, dan Perplexity semakin mendominasi cara orang mencari informasi, crawl budget tetap relevan karena semua AI search engine pada akhirnya mengambil data dari index web yang sudah ada. Konten yang tidak pernah diindeks tidak akan pernah muncul sebagai referensi di AI search manapun. Jadi optimasi crawl budget bukan hanya soal ranking Google tradisional, tapi juga soal visibilitas di ekosistem AI search secara keseluruhan.
Semakin Banyak Konten, Semakin Kritis Crawl Budget
Strategi AEO dan GEO yang saat ini banyak dijalankan mendorong tim konten untuk memproduksi lebih banyak artikel, FAQ, dan halaman topical. Semakin besar volume konten, semakin kritis pengelolaan crawl budget. Olakses memastikan setiap strategi konten yang dijalankan klien juga disertai audit teknis crawl budget agar setiap halaman yang diproduksi benar-benar dirayapi dan diindeks oleh Googlebot, bukan hanya tersimpan di CMS tanpa pernah terlihat search engine.
Mau Audit Crawl Budget Website Anda?
Tim Olakses siap membantu Anda mengidentifikasi halaman mana yang membuang crawl budget dan menyusun strategi teknis untuk memastikan konten prioritas Anda dirayapi dan diindeks Google dengan benar. Mulai dari audit log file, analisis sitemap, hingga implementasi perbaikan teknis secara menyeluruh.
FAQ: Pertanyaan yang Sering Diajukan tentang Crawl Budget
Q1: Apakah crawl budget berbeda untuk setiap search engine?
A1: Ya. Setiap search engine, termasuk Google, Bing, dan lainnya, memiliki crawler sendiri dengan alokasi resource yang berbeda. Crawl budget yang dibahas dalam konteks SEO biasanya merujuk pada alokasi dari Googlebot secara spesifik.
Q2: Bagaimana cara paling cepat mengecek apakah website saya punya masalah crawl budget?
A2: Buka Google Search Console, masuk ke menu Settings > Crawl Stats. Lihat rata-rata halaman yang dirayapi per hari dan bandingkan dengan total halaman website Anda. Kalau rasionya jauh di bawah ekspektasi, ada indikasi masalah crawl budget.
Q3: Apakah noindex otomatis membebaskan crawl budget?
A3: Noindex mencegah halaman diindeks, tapi Googlebot tetap akan mengunjungi halaman tersebut kecuali diblokir lewat robots.txt. Untuk benar-benar menghemat crawl budget, gunakan robots.txt untuk blokir halaman yang tidak perlu dikunjungi sama sekali.
Q4: Berapa banyak URL yang ideal dalam XML sitemap?
A4: Sitemap hanya boleh berisi URL yang aktif, bisa diakses, dan benar-benar ingin Anda indeks. Tidak ada batas “ideal” dalam jumlah, tapi kualitas URL dalam sitemap jauh lebih penting daripada kuantitas. Jangan masukkan URL noindex atau URL yang diblokir robots.txt ke dalam sitemap.
Q5: Apakah crawl budget memengaruhi ranking langsung?
A5: Tidak secara langsung. Crawl budget memengaruhi seberapa cepat dan seberapa banyak halaman Anda yang diindeks. Halaman yang tidak diindeks tidak bisa ranking. Jadi dampaknya ke ranking bersifat tidak langsung tapi sangat nyata, terutama untuk website baru atau website yang sering memperbarui konten.
Q6: Seberapa sering saya perlu audit crawl budget?
A6: Untuk website yang aktif menambah konten, audit crawl budget idealnya dilakukan setiap kuartal. Untuk website statis yang jarang berubah, audit tahunan sudah cukup. Kalau Anda sedang mengalami penurunan indexing yang tiba-tiba, segera lakukan audit meskipun belum waktunya.
Q7: Apakah menggunakan CDN bisa meningkatkan crawl budget?
A7: Ya, secara tidak langsung. CDN mempercepat response time server Anda, yang memberi sinyal positif kepada Googlebot bahwa website Anda bisa dirayapi lebih agresif tanpa membebani server. Hasil akhirnya adalah crawl capacity limit yang lebih tinggi untuk website Anda.

Muhammad Dwiki Septianto is an SEO Specialist at Olakses with a background in Informatics Engineering from UIN Bandung. Certified in Digital Marketing (BNSP), he specializes in on-page and technical SEO, content optimization, and cross-functional coordination between content and development teams.